今日は、暗号の話を書きたいと思います。
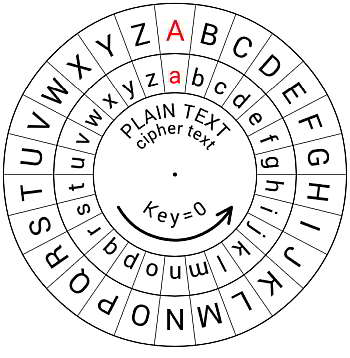
シーザー暗号をExcelで作る
シーザー暗号(Caesar cipher)は、単一換字式暗号の一種で、暗号化する元の文章、すなわち、「平文」の文字を特定の文字だけシフトして暗号文をつくる暗号です。この暗号を自動作成するExcelシートを公開します。
シーザー暗号は、カエサル・シフト暗号(サイファー)とも呼ばれています。そう、「ブルータス、お前もか」で知られるローマ時代のガイウス・ユリウス・カエサル(英語読み「ジュリアス・シーザー」)が使っていた暗号です。
文字をある数だけシフトして表記することでまったく意味不明の文章になります。
例えば、「This is a pen」 を3文字シフトすると、つまり、「A」を「C」に、「B」を「D」に順次読み替えていくと、「VJKU KU C RGP」になり、まったく意味が分からなくなります。まさに、暗号です。
何文字シフトするのかの鍵(キー)を相手に伝えておけば、簡単に復号できます。しかし、シーザー暗号では、鍵の候補が二十五通りしかなく、暗号としては強力とは言えません。
暗号としては、初歩の初歩というレベルのシーザー暗号ですが、Excelで簡単にできそうだったので暗号化プログラムを作ってみました。
もっと簡単に作れると思ったのですが、思いのほか手間取ってしましました。数字ではなく文字を置き換えるので、通常の関数ではエラーが出てしまう。さらに、単語間の空白をどう扱うかがポイントでした。今回は、コンマ、ピリオドを含まないものを作成しましたが、アルファベット26文字以外の記号・数字を含めれば40文字くらいになります。これをランダムに配置すると、暗号キーとの照合がより複雑になります。公開するExcelシートでは「K列」がそれに該当します。「K列」のアルファベットは順に並んでいますが、これをランダムに配置すると、キーを探すのが大変になります。元のアルファベットの並び替えを自由にすると4 x 10^26 通りを上回る方法が可能で、コンピュータを使わなければ解読できそうにありません。
アルファベットを使う単一換字式暗号には大きな弱点があります。それは、文字の使用頻度です。英和辞書のふちを見ると分かるように、「S」ではじまる見出し語が最も多い。次が「C」です。このため、暗号で使われている最も多く使われている文字が、平文の「S」である可能性が高くなります。このように推測しながら文字を特定していきます。また、英語ではQの次には必ずUがきます。このような英語独特のルールを元に可能性のある組み合わせをさらに絞り込んでいきます。
ドイツ語の場合は、「S」と「A」の見出し語が同じくらいあります。また、スペイン語では、「A」と「C」が最も多く、「S」は少ないという特徴があります。これは、「S」ではなく「Es」と書く場合が多いためと思います。
なお、辞書の文字別見出し語数と実際の文章における度数とではかなり違いがあります。
下の表は、実際の英文で使われる単語の最初の文字の出現頻度は、E⇒T⇒A⇒O⇒I⇒N⇒S⇒H⇒Rという順になります。
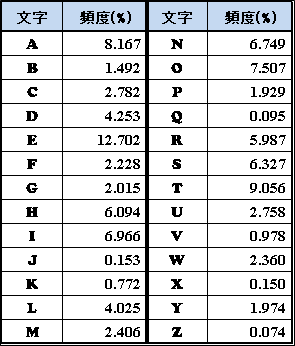
このように、アルファベットを使っていても、何語で暗号が書かれているかを推測することが暗号解読の最初のステップとして重要になります。
今の時代、コンピュータにより、この程度の暗号は、簡単に解読されてしまいます。でも、暗号化のプロセスを知るのには良い勉強になりました。
このエクセルシートの使い方は、シートに記載しています。
「こんなの、何に使うの?」という声が聞こえてきそうです。でも、これを作りながら、日本人なら解けるけれど、外国人には解けないという暗号も作ることができそうな気がしました。

Excelシートのダウンロードはこちらから。
ダウンロードパスワードは、「nekocat」です。
なお、このシートは、暗号化はできますが、復号はできません。時間があれば作ろうかと思いますが、とりあえずアップロードします。 復号化できるシートを追加しました。暗号を送る相手には、暗号文とは別に「キー」を送る、あるいは、事前にキーを決めておくことで、簡単に暗号を平文に復号できます。
Excelシートにはマクロは使っていません。ロックしていないので、関心のある方は式をご覧下さい。
和歌を使った暗号作成Excelシートを作る
縦横のマス目を座標として使って文字を変換していく方法があります。紀元前2世紀に考案されたポリュビオス暗号は、5×5=25のマス目にアルファベットを記入し、各アルファベットにそのアルファベットが入っているマス目の行番号と列番号とを対応させる換字式暗号です。
日本では武田信玄がこれと同じような暗号を用いました。日本語のいろは四十七文字に対応させるため、7×7=49のマス目を使います。また、縦横の番号の代わりに文字を割り当てます。この文字の割り当て方がキーとなります。
このキーには、和歌の下二句である七・七が使われることもありました。キーが何かさえ相手に伝えておけばカンタンに復号できます。
このプログラムをExcelで作ってみました。
和歌の下二句(七・七)を入力すると換字表が完成。あとは、縦横の座標の交わる文字を表すために、縦横の文字を決めていきます。つまり、縦横の二文字で交差点の一文字を表すことになります。
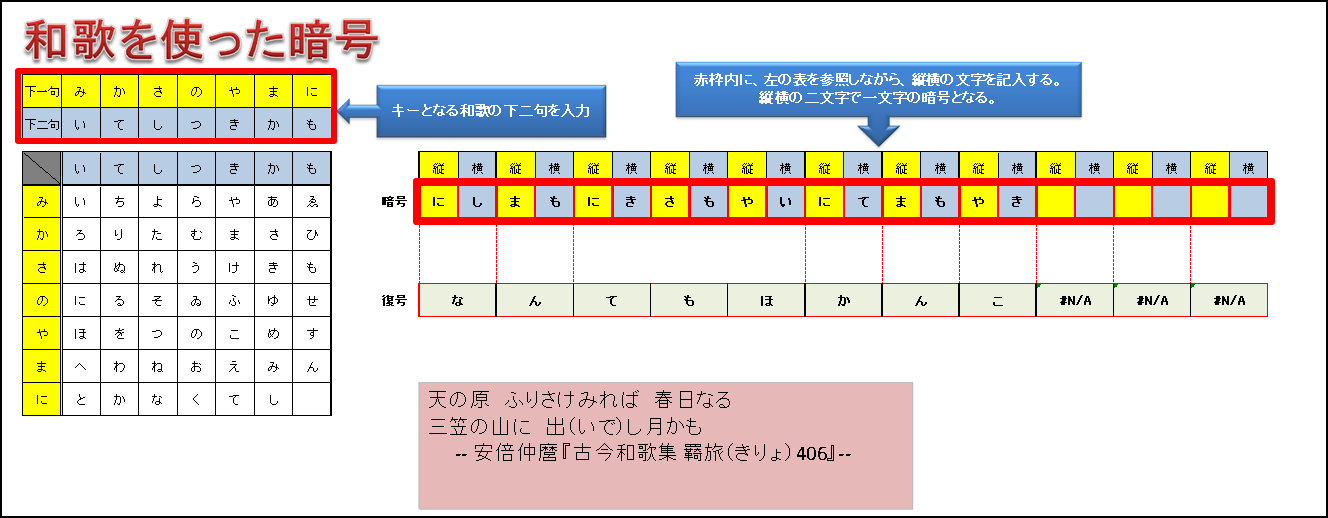
表示している例では、『天の原 ふりさけみれば 春日なる 三笠の山に 出(いで)し月かも』(安倍仲麿 『古今和歌集』から、歌の下句『みかさのやまに』を列方向、『いてしつきかも』を行方向に割り振っています。
七文字の重複使用はできません。例えば、紀貫之の『・・・・・ 香ににほひける』は『に』が七文字の中で重複して使われているので、この歌はキーとしては使えません。
未知の言語は解読できない
太平洋戦争では、日本軍の暗号はアメリカ軍にほとんど解読されていました。現代のコンピュータを使えば、さらに簡単に解読可能です。しかし、実は、解読されない秘策があります。
暗号解読コンテストがありますが、その前提は、「既知の言語」から「既知の言語」に解読すること。現代のコンピュータをもってしても、「未知の言語」から「既知の言語」に解読はできません。
解読されない秘策とは何か。それは、言語体系が異なる少数言語を用いることです。その道の専門家ですらやっと解読できるという少数言語を用いれば、敵方にはその知識を持っている人がいません。このため、解読プログラムを作ることができません。日本にはたくさんの方言があります。日本の北と南ではまったく異なる言葉を話しますし、近隣の県の人でも理解できないことも多々あります。沖縄弁と津軽弁を組み合わせた暗号を作ったらどうでしょう。そのような言葉を理解できる人はほとんどいないので、そもそも暗号化と復号化が難しそうですが、機械を使えばできます。さらに、明治時代の津軽弁と戦前の沖縄弁という時期の違う言葉の揺らぎを使うと、より難しい暗号が作れそうです。
実は、この方言を使う暗号方式は、戦国時代から使われていたようです。管理人が思いつきそうな方法は、既に誰かがやっていたということでしょうか。
第二次世界大戦の末期、同盟国ドイツとの通信で実際に鹿児島弁が暗号として使われていました。戦局の悪化により、ドイツの通信所が暗号配列を間違える不手際をしでかしたことから通常の暗号通信ができなくなったため、国際電話を使うことになったのですが、その際の盗聴を防ぐ苦肉の策でした。外務省は、盗聴されても理解できない言葉として、最も標準語から遠い鹿児島弁を選び、ドイツ駐在の日本大使館員と鹿児島弁を使った暗号電話で情報の交換を行いました。(吉村昭、『深海の使者』)
この方式の暗号は、1939年(昭和14年)の天津での会議でも使われていたものです。日本の暗号は、戦国時代から進化していなかったということでしょう。
日本軍もアメリカ軍の暗号はほとんど解読していました。しかし、解読できない暗号もありました。それはアメリカン・インディアンのナバホ族が使っていたナバホ語によるものでした。
いまだに解けない暗号「ビールの暗号」
暗号の世界は奥深く、未だに解読できない暗号もいくつかあります。その一つが海賊が残した財宝に関わるものだとしたら、俄然興味が湧きます。
解けない暗号として「ビールの暗号」があります。これは、19世紀の開拓時代のアメリカで、カーボーイが埋蔵した2千万ドルの宝にまつわる暗号です。この時代の暗号など、今のコンピュータを使えば簡単に解けるはず。ところが、これが解けない。暗号は数字群なのですが、暗号解読に必要な「キー」が失われてしまったため解くことができない。
「ビールの暗号」について、もう少し詳しく書きましょう。
「これは1884年にアメリカのウッドという人物が書いた小冊子に載っている話である。それによると、偶然入手した文書から1820年頃、当時のペンシルバニア狩猟協会長ビール(Beale)が会員と相談の上、会の財産である金銀宝石など(当時の額で)30万ドル相当の宝物を某場所に埋めたことを知った。それについて三通の暗号文があり、第1の文章を解読して、この話が分かった。第2の文章が埋蔵地を示し、第3の文章が関係者だという。」(『暗号の数理、一松信、講談社、2005、p.73』)
暗号についての本にはもっといろいろ書いてありますが、ざっとこんな内容にまつわる暗号です。
第1の暗号は、本を「鍵」として解読に成功しました。しかし、残りの2枚の解読ができない。違う方法で暗号化されているようです。
何にでも関心を示す管理人がこの解読をやってみました(笑)。何事もやってみなければ分からない。
埋蔵場所が書かれているとされる暗号の1枚目の紙を使います(上の説明では2枚目の暗号。本によって書き方が異なる)。たくさんの数字が並んでいます。それらを抽出して特徴を調べます。

Source: Wikipedia “Beale ciphers”, Beale’s first cryptogram
数字の総数: 519
最 小 値: 0
最 大 値: 2906
最頻出数字: 18(8回)、19(7回)、216(7回)
無い数字: 20, 32, 45, 47, 53, 54, 57, 75, 91 (0~100で9個使われていない)
先ず、数字総数ですが、519です。これは仮に”英文”としてWordに打ち込むと5行程度の文章を作れる文字数です。財宝のありかを記すためにはぎりぎりの文字数と思われます。これから分かることは、余計な数字(ダミー数字)は入っていない、あるいは、かなり少ないということです。
次に、数字の幅です。0から2906までとても広いレンジを使っています。総数字数519の6倍ものレンジを使って暗号文を作っています。なぜ、これだけのレンジが必要だったのか、暗号作成者側に立って考えます。これについての考察は、ひとまず保留します。
数字の頻度分布を見てみます。最も多いのが「18」で、8回使われています。これを「E」と仮置きして推測します。次に、使われていない数字を見ます。アルファベット26文字を考えると、使われていない最初の数字「20」が目を引きます。これを「Q」と仮置きします。この「E」と「Q」との位置関係で有意な傾向があるか検討します。
このタイプの暗号文は、(もし、本物だとすると)、それほど複雑ではないと考えられます。暗号化も複合化もそれほど複雑ではない方法が採られている、と考えられます。そもそも、カーボーイが隠した財宝なので、高度な暗号化の必要性を感じません。
数字のレンジを広げているということは、数字を足したり引いたりするような暗号ではなく、「読まない」というような単純なルールが使われているように思います。例えば、4桁の数字は千の位と一の位のみ使い、百の位と十の位の数字は読まない。4桁の数字の総数は、19個です。このルールだと次の疑問をうまく説明できます。なぜ、2千台までの数字が使われ、3千台以降の数字はないのか。
アルファベット26文字と空欄、コンマ、ピリオドを加えた29文字の置き換え問題のような気がします。だから、3千台は不要なのです。
そして、この4桁の部分にキーが隠されているように思います。4桁の数字は19個しか使われていません。
管理人の謎解きは、ここで一旦終了です。暇なときに考えて見ます。
ここまで書いておきながら、今さらという感じですが、実は、「ビール暗号」は偽物であると証明されているようです。ある学者が1980年代に計量言語学の立場から、ビールの文章と暗号を公開したウッドなる人物の文章とをコンピュータを駆使して徹底的に比較検討したところ、両者の文章が酷似していることが判明しました。これにより、ウッド氏がねつ造したものと結論づけられました。
まあ、このようなことを言う学者はたまにいます。1980年代はコンピュータが身近なツールとして登場した時期であり、「コンピュータを駆使して」、「徹底的に解明」することが何でも可能と思われていた時代です。1981年からコンピュータを使ってノストラダムスの預言詩の解読を行ったドイツ人マンフレッド・ディムデ氏が「コンピュータが解いたノストラダムス全警告」なる本を出版したりしています。このディムデ氏は今も毎年本を出版しており、ドイツでは有名人のようです。
“1980年代”の学者が、”コンピュータを駆使して”解析した成果は、信用できないと思います。
ビールの暗号は本当にウッド氏のねつ造だったのでしょうか。管理人は違うように思います。この暗号はいずれ誰かが解読するように思えるのですが。
オランダの言語学者アウグスト・ケルクホフス・フォン・ニーウエンホンは、「暗号システムの安全性は、暗号化アルゴリズムを秘密にできるかどうかは関係しない。暗号システムの安全性は、鍵の秘密を守れるかどうかにかかっている。」と著書『軍用暗号』の中で述べており、これは「ケルクホフスの原理」と呼ばれています。
暗号を解読できる前提として、最終的には、暗号の受け手が理解できる言語になっているということが挙げられます。暗号解読の基本は、復号からはじまるようです。それは、「既存の言語」ということが大前提です。
コンピュータが”未知の言語の規則性”を見つけて、翻訳してくれる、などはかなり難しいと思います。なぜなら、”不規則性が言語の特徴”だからです。わずか100年前に書かれた日本語を私たちはまともに読むことができません。明治時代の小説など、現代口語訳しないと読めません。言語は、常に揺らいでいて、50年、100年という年月の間に、大きく変化します。
「巡回セールスマン問題」というのをご存じでしょうか。例えば、国内の30箇所の支店を最短ルートで巡回するための最適ルートを求める問題です。ところが、これがとても難しい問題で、経路が10の30乗通りあります。日本が世界に誇る、浮動小数点数演算を1秒あたり1京回(10の16乗)おこなう処理能力のあるスーパーコンピューター「京」を使っても1000万年以上かかるそうです。それを短時間で解くことができるとして期待されているのが量子コンピューターと呼ばれるもので、現エーザイ筑波研究所主幹研究員の門脇正史らが1998年に理論を提唱し、カナダの企業D-Wave Systemsが実用化し、Googleが本格的に開発に乗り出しているようです。
「巡回セールスマン問題」を観ていると、コンピーターなら何でも解けるというのは幻想だということが分かるのではないでしょうか。

上の写真は埼玉県の理研の一般公開で撮影したコンピューターです。残念ながら、スパコン「京」は神戸にあるので撮影できませんでした。
どんなに巧妙に作られた暗号であっても、復号されなければ意味がありません。そして、このことが暗号解読の原点になっています。つまり、使用している言語文字が持つ特徴は、暗号にもそのまま反映されてしまうというリスクがあります。例えば、英語の文章に現れる文字の頻度です。上でも述べたように、これには諸説あるのですが、一般には、E、T、A、O、I、N、S、H、R、D、L、Uの順に多く出現すると言われています。これらをつないで、「ETAOIN SHRDLU」という12文字の造語がつくられました。試しに、このキーワードでGOOGLEで検索してみて下さい。5万件ヒットします。
この最出現率の12文字を使った最も自然な組み合わせの語は、「South Ireland」だそうです。
わずか26文字しかないアルファベット、そして、そのうちの12文字で、この程度の単語しか作れないのですから、英語はいかに語彙が少ない言語かが分かります。
日本語では、「いろは四十七文字」があります。一度も重複せずにすべての文字を用いた「いろは歌」がいかにすごいものであるか、改めて思い知らされます。そして、「いろは歌」の優美な響きを超える新たな組み合わせは未だ見つかっていません。いくつか考案されていますが、「いきなり低レベル」という印象で、比較の対象にすらなり得ません。
「いろは歌の暗号」は昔から有名で、その作成者については諸説あるものの、定説には至っていません。
暗号とは
暗号とはそもそもなんなのでしょうか。一松信の定義をお借りすると、「暗号とは、文章を構文上の立場から、文字あるいは単語などの構成要素の列と見なし、それらに他の文字や記号への変換や、順序の変換のような復元可能な操作を施す秘密の通信手法、またはそれで作られた文書のこと」(『暗号の数理』<改訂新版>、一松信、講談社、2005、pp.22-23)と言えるようです。様々なケースを想定した上での定義になっています。
日本語では「暗号」という一つの言葉しかないのですが、英語では、暗号法を「クリプトグラフィー:cryptography」、暗号文を「サイファー:cipher」といいます。また、Wikipediaによると、秘匿通信には、主にステガノグラフィ(steganography)、コード (Code) 、サイファ(cipher, cypher)という3種類の方法があると説明されています。
| 1.ステガノグラフィ | 通信文を人目に付かない場所に記録する。画像などに情報を埋め込む電子透かしなど。また掲示板でよく見かける縦読みも一見して普通の文章の中に見えるためステガノグラフィーの一種と言える。 |
| 2.コード | 通信文の単語やフレーズを、事前に決めておいた言葉・記号で置き換える。これらは符牒や隠語とも呼ばれる。 |
| 3.サイファ | 通信文を、意味とは関係なく、所定のアルゴリズムに従って、(1つまたは複数の)文字やビットごとに置換や転置を行うことで、読めない文に変換する。 |
Source: Wikipedia

