
文書を画像形式で保存し、その画像をネット上に公開しているサイトがかなりの数存在します。
画像に写っているテキストは、当然読むことはできますが抽出はできません。
また、手持ちの画像ファイルの中のテキストを抽出したいということもたまにですがあります。
画像の中のテキストを抽出する場合、通常は、OCRソフトを使います。以下、対象言語は英語で話を進めます(日本語の抽出は難しいので)。
「Adobe Acrobat Pro」を使って抽出する方法
通常は、「Adobe Acrobat Pro」のOCR機能を使って英文テキストを抽出します。
サンプルとして、Wikipediaページの冒頭にある寄付を求めるテキストを使います。これは、png形式で画像として保存しています。

このファイルを「Adobe Acrobat Pro」で開きます。PDFファイルだけでなく、画像ファイルも開くことができます。
メニューバーの[文書]⇒[OCRテキスト認識]⇒「OCRを使用してテキストを認識」と進み、
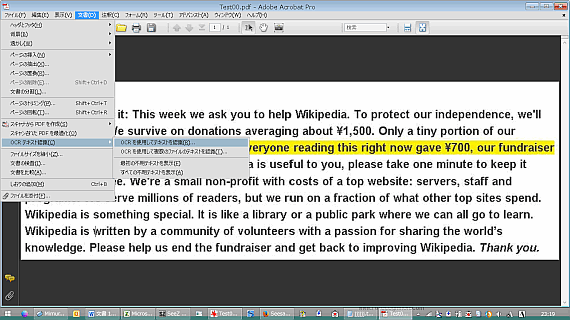
「テキスト認識」ダイアログが開くので、認識する対象のページを設定します。今回は画像なので、「現在のページ」⇒[OK] 認識が始まり、終了すると、文字として認識され、コピーすることが可能になります。
「IrfanViewのプラグイン」を使って文字を抽出する方法
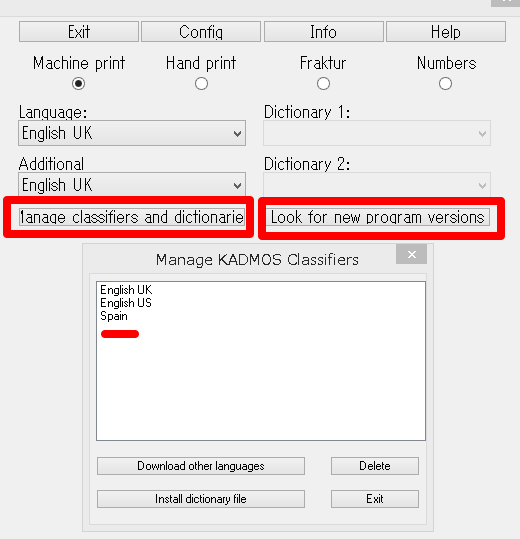
フリーの画像ビューアであるIrfanviewにOCRプラグイン『KADMOS ICR/OCR SDK』がインストールされていれば、画像ファイルから英文テキストを簡単に抽出できます。ただし、このプラグインでは、一度に1000文字しか抽出できないので、長いテキストを抽出する場合には、分割して抽出する必要があります。抽出に使われるOCRの性能はとても良く、優れものです。
1.最初に、上のリンクからOCRプラグインをダウンロード、インストールします。
2.画像を読込み、[オプション]⇒[OCRの開始]

3.上の画像で、黄色い部分を選択します。右側に抽出結果としてコピー可能
なぜ、この原稿を書いているかというと、「Adobe Acrobat Pro」で抽出できないPDFファイルに出くわしたからです。PDF原稿は比較的キレイなのに、OCRがうまく抽出できない。最初はあきらめたのですが、IrfanViewでも抽出できることを思い出し、やってみたら、きれいに抽出できました。
理由はよく分かりませんが、外国語テキストの抽出で困ったときには試して見る価値がありそうです。
抽出したテキストをつなげる方法
上記の二つの方法のどちらも、抽出したテキストは行単位になっています。テキスト量が少なければ、改行を削除して、ひとつの文章になるように修正しますが、テキスト量が多いとこれは大変な作業になります。
そこで、これをエクセルのマクロを使って、一行にします。何百行でも一瞬で一行になります。あとは、それをWordなどに貼り付け、段落を入れ、スペルチェックをかけて、適宜、修正します。ここまでできると、誤抽出部分はかなり減っているので、後の作業がとても楽になります。
この行単位になったテキストを一行にする方法については過去記事『PDFファイルのテキストをコピーするときに役立つテキストの結合方法』に書きました。Excelブックも公開しているのでご利用下さい。至れり尽くせりのサイトです(笑)。

